Binary Outcome, Two Independent Groups,
Case-Control Studies
Background
� Cohort and Case-Control Studies � 2-by-2 Table and Formulas � Illustrative Data Set (BD1NEW.REC)
Descriptive Methods
� Cross-Tabulation � Exposure Proportions and Odds Ratio
Inferential Methods
� Estimation � Hypothesis Testing
Power and Sample Size Requirements
Exercises
Background
Cohort and Case-Control Studies
In the previous chapter we considered a binary outcome from two independent groups. Data were derived in a forward
(longitudinal) or adirectional (cross-sectional) manner. Incidences or prevalences were calculated and compared in two
groups. One group was denoted as the "exposed group" and the other group was denoted as the "unexposed group." The
association between the exposure and the disease was summarized in the form of a relative risk or odds ratio.
In this chapter we estimate the odds ratios for an exposure and disease in a "backward direction" using the case-control
method. Like forward-directional studies, case-control (backward-directional) studies estimate the association between an
exposure and disease. However, in contrast to cohort (forward-directional) studies, case-control studies start with people
with incidence (new) cases of disease and controls without disease. The odds of exposure are then compared to the form of
an exposure odds ratio.
To clarify the logic behind this approach, let us use conditional probability notation to help clarify the logic behind this
approach. Let P(E+|D+) denote "the probability of exposure positive given disease positive." Let P(E+|D-) denote "the
probability of exposure positive given disease negative". Notice that these conditions are based on the known disease status
of subjects. We have therefore forfeited the ability to calculate incidence and thereby absolute risk. An alternative approach
toward risk analysis is needed. Alternative analysis is provided in the form of the exposure odds ratio.
The odds of an event is its probability of occurrence divided by the probability of its complement. For example, if the
probability of being exposed in 0.25, the odds of exposure = 0.25 / (1 - 0.25) = 0.25 / 0.75 = 0.3333.
The exposure odds ratio (EOR) is the odds of exposure in cases divided by the odds of exposure in controls. This is equal
to:
odds of exposure in cases P(E+|D+) / P(E-|D+)
EOR = ---------------------------- = --------------------
odds of exposure in controls P(E+|D-) / P(E-|D-)
We can now show that this exposure odds ratio is equivalent in its interpretation to the disease odds ratio.
Recall that the disease odds ratio (DOR) is:
odds of disease in the exposed P(D+|E+) / P(D-|E+)
DOR = ---------------------------------- = --------------------
odds of disease in the unexposured P(D+|E-) / P(D-|E-)
By applying Bayes' law, we have:
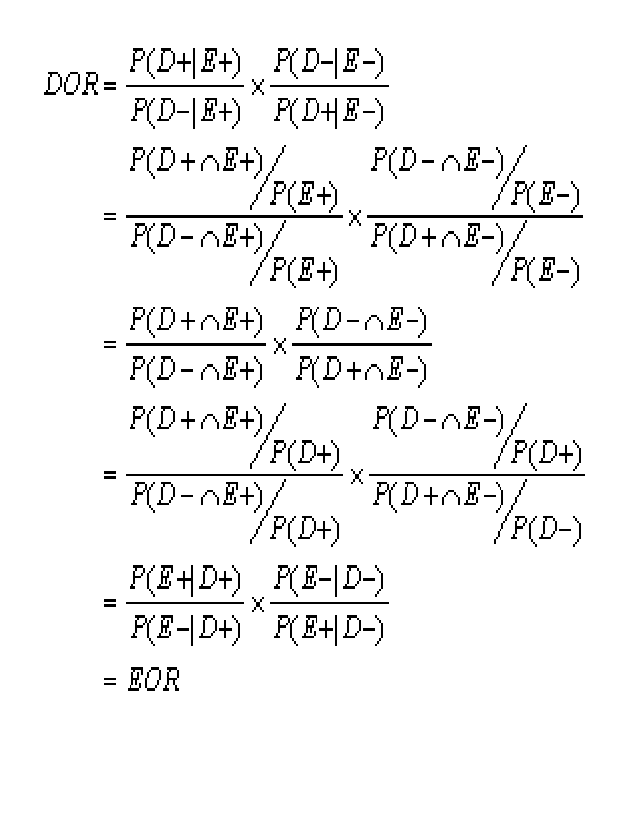
Thus, disease odds ratios and exposure odds ratios have the same general interpretation. Moreover, when the disease is rare
(say, incidence < 5%), the DOR is approximately equal to the RR. Under this "rare disease assumption," the exposure odds
ratio can be interpreted as a relative risk.
2-by-2 Table and Formulas
Like cohort studies, data from case-control studies are displayed in 2-by-2 tables with cells labeled are as follows:
|
Cases |
Controls |
|
| Exposure + |
a |
b |
n1 |
| Exposure - |
c |
d |
n2 |
|
m1 |
m2 |
N |
Let p1 represents the exposure proportion in cases:
a
p1 = ----
m1
Let p2 represents the exposure proportion in controls:
b
p2 = ----
m2
The exposure odds ratio parameter (EOR) is:
p1 / (1 - p1) a / c ad
EOR = ------------ = ------ = ----
p2 / (1 - p2) b / d bc
Illustrative Data Set (BD1NEW.REC)
To illustrate techniques in this chapter, let us consider a case-control study of esophageal cancer from Tuyns (1977) which
was made popular by Breslow & Day (1980, Chapter 4). This case-control study considers 200 cases with esophageal
cancer and 775 community-based controls. Both cases and controls were administered a detailed dietary interview which
contains questions about alcohol consumption, tobacco use, and other factors. Data pertinent to our illustrative example are
contained in BD1NEW.REC as variables CASE (1 = case, 2 = control) and ALCHIGH (alcohol consumption dichotomized at
80 grams per day: 1 = high, 2 = low).
Descriptive Methods
Cross-Tabulation
To cross-tabulate the data, issue the command:
EPI6> TABLES <exposure> <disease>
where <exposure> represent the name of the exposure variable and<disease> represents the name of the disease
variables.
For our illustrative data set, issue the command:
EPI6> READ BDNEW
EPI6> TABLES ALCHIGH CASE
The first part of the output contains the 2-by-2 table:
CASE
ALCHIGH | 1 2 | Total
-----------+-------------+------
1 | 96 109 | 205
2 | 104 666 | 770
-----------+-------------+------
Total | 200 775 | 975
Exposure Proportions and Odds Ratio
From the above table we see that the exposure proportion in cases (p^1) = a / m1 = 96 / 200 = .480. The exposure
proportion in controls (p^2) = b / m2 = 109 / 775 = .141. The exposure odds ratio (OR^ ) = ad / bc = (96)(666) / (109)(104)
~= 5.6. This suggests a strong positive association between high alcohol consumption and esophageal cancer; the risk of
esphageal cancer in with high alcohol consumers is 5.6 times that of low consumers.
Inferential Methods
Estimation
The point estimate and 95% confidence interval for the OR are printed below the 2-by-2 table. Output for the illustrative
data set shows:
Single Table Analysis
Odds ratio 5.64
Cornfield 95% confidence limits for OR 3.93 < OR < 8.10
Maximum likelihood estimate of OR (MLE) 5.63
Exact 95% confidence limits for MLE 3.94 < OR < 8.06
Exact 95% Mid-P limits for MLE 3.99 < OR < 7.95
Probability of MLE >= 5.63 if population OR = 1.0 0.00000000
The common point estimate for OR = 5.64. The maximum likelihood estimate (MLE) = 5.63. The 95% confidence interval
for the OR is computed using three different methods (Cornfield's, Maximum Likelihood Method, and mid-P Maximum
Likelihood Method). In most instances, intervals will differ only slightly. The 95% confidence interval by Cornfield's method
for our illustrative example = (3.9, 8.1).
The relative risk estimates printed below the odds ratio statistics should be ignored.
When working with data that have already been cross-tabulated, statisical results can be computed with
StatCalc|Tables| or EpiTable|Study|Case-control|Unmatched |.
Hypothesis Testing
The null and alternative hypotheses to be tested are:
H0: OR = 1
H1: OR not = 1
A chi-square test or Fisher's test is performed, as discussed in the previous chapter. The results of the chi-squared results for
the illustrative data set:
Chi-Squares P-values
----------- --------
Uncorrected: 110.26 0.00000000 <---
Mantel-Haenszel: 110.14 0.00000000 <---
Yates corrected: 108.22 0.00000000 <---
indicating statistical significance.
Suggestion: See the prior chapter for comments regarding the use of chi-square tests and Fisher's exact test.
Power and Sample Size Requirements
The power of case-control study depends on the (a) expected exposure proportions in cases and controls, (b) group sample
sizes, and (c) the alpha level of the test. Various formulas and calculators ask for this information in different ways. In using,
EpiTable|Sample|Power calculation|Case-control study, for example, the user is asked for:
- the number of cases (m1)
- the allocation ratio of controls to cases (m2 /m1)
- the "odds ratio worth detecting") (OR)
- the exposure proportion in controls (p2)
- the alpha level of the test (alpha)
Similarly, EpiTable|Sample|Sample Size|Case-control study can be used to determine sample size
requirements to detect an OR worth detecting with any give level of power.
For example, if we wish to detect an OR of 2 using an allocation ratio of 1:1 in a population with an expected exposure
proportion among non-cases of .25 (and assuming alpha = .05 and power = .8), then m1 = m2 = 165. (Total sample size = 330).
Exercises
(1) DOLL1950: Smoking and Lung Cancer (Doll & Hill, 1950)
A classical case-control study of smoking and lung cancer found that 647 of 649 lung cancer cases were smokers while 622
of 649 non-cancer controls smoked.
- (A) Display these findings in a 2-by-2 table.
- (B) Calculate exposure proportions in cases and controls (p^1 and p^2, respectively).
- (C) Using EpiTable, compute the exposure odds ratio and its 95% confidence interval. Interpret your results.
(D) Test the hypothesis of no association. List the null and alternative hypotheses; set alpha, compute the test statistics and p
value, state your conclusion.
(2) ESOPH_CA.REC: Esophageal Cancer and Tobacco Consumption (Tuyns,
1977; Breslow & Day, 1980)
This is the same data set discussed in the chapter to illustrate case control methods. Currently, let us look at tobacco
consumption exposure in which we dichotomize exposure at 20 grams per day (TOB2: high/vhigh = 80+
gms/day, low/med = < 80 gms/day). Case status is contained in ESOPH_CA (1 = case, 2 =
control).
- (A) Calculate exposure proportion in cases and controls.
- (B) Compute the odds ratio and its 95% confidence interval.
- (C) Perform a full test of association. (List the null and alternative hypotheses . . .)
- (D) Summarize your results in narrative form.
(3) ESOPH_CA.REC: Esophageal Cancer and Age (Tuyns, 1977; Breslow &
Day, 1980)
Data are once again from the French case-control study of esophageal cancer. For this analysis, let us dichotomize age at 55
years (AGE2: "older" = 55+ years of age, "younger" < 55). Once again,
- (A) Calculate exposure proportion in cases and controls.
- (B) Compute the odds ratio and its 95% confidence interval.
- (C) Perform a full test of association. (List the null and alternative hypotheses . . .)
- (D) Summarize your results in narrative form.
(4) BD2.REC: "Breslow & Day 2" (The Oxford Childhood Cancer Survey)
(Stewart & Kneale, 1970; Kneale, 1971; Breslow & Day, 1980, p. 238)
Data come from a case-control study of childhood leukemia and lymphoma and in utero exposure to X-rays. Cases are
children less than ten years of age in England and Wales that occurred during the period 1954-65 (variable CASE: 1 = yes, 2
= no). For each case, a neighborhood control of the same age and year of birth was selected. Exposure status is based on
whether mothers were exposed to X-rays during pregnancy (variable XRAY: 1 = yes, 2 = no). Perform a complete
case-control analysis, similar in type to the ones completed above.
(5) IUD: Intrauterine Device Use and Infertility (Cramer et al., 1985; Rosner,
1990, p. 381)
A study of contraceptive use and infertility found prior use of IUDs in 89 out of 283 infertile women, compared with 640
out of 3833 (fertile) control women.
- (A) Calculate relevant case-control statistics (p^1, p^2, OR^, 95% confidence interval for OR).
- (B) Test H0: EOR = 1. (Report all steps of the hypothesis testing procedure, starting with the statement of H0, finishing with
the categorical conclusion to the test.)
- (C) Summarize your results.
(6) PROSTATE.REC: Vasectomy and Prostate Cancer (Data source: Zhu et
al., 1996)
A case-control study was conducted to help assess the potential relationship between vasectomy and prostate cancer.
(Although cases and controls were matched on birth year and membership status in the original study, this is ignored in
thisexercise. Fortunately, this does not materially alter its results.)
- (A) Calculate the exposure proportions in cases and controls.
- (B) Calculate the odds ratio and its 95% confidence interval.
- (C) Test the hypotheses of no association. (Set up the null and alternative hypotheses, select an alpha level, report a test
statistics and p value, and state the conclusion.
- (D) In plain language, summarize your results.
- (E) What was the power of this analysis to detect an odds ratio of 1.5? (Assume a two-sided alpha level of .05.)
- (F) Calculate the sample size requiremented to uncover the following odds ratios with power = 80%.
- OR = 1.3
- OR = 1.5
- OR = 2.0
- OR = 3.0
(7) ASBESTOS.REC: Asbestos Exposure and Lung Cancer (Hypothetical
data)
Data are from an case-control study of lung cancer and asbestos exposure. The data set includes information on smoking
(SMOKE: + / -), asbestos exposure (ASBESTOS: + / -), and lung cancer (LUNGCA: + / -)
(A) Calculate the odds ratio of lung cancer associated with smoking. Include a 95% confidence interval, and interpret your
findings.
(B) Calculate the odds ratio of lung cancer associated with asbestos exposure. Include a 95% confidence interval and
interpret your findings.
(8) BRAINTUM.REC: Electric blanket use and brain tumors in children
A case-control study by Preston-Martin et al. (1996) was done to assess potential risks for brain tumors in children
(BRAINTUM: Y/N). One potential risk factor was electric blanket and water bed heater use (ELECBLANK: Y/N).
Data are contained in BRAINTUM.REC.
(A) Cross-tabulate the data and display it in a 2-by-2 table.
(B) Calculate exposure proportions in cases and controls.
(C) Compute the exposure odds ratio estimate and a 95% confidence interval for the OR. Interpret your results.
(D) Test the data for significance. List the null and alternative hypotheses, set an alpha level, compute the test statistic and p
value, and state your conclusion. Interpret your results.
(E) Calculate the study's power to uncover odds ratios of:
- (i) 1.1
- (ii) 1.2
- (iii) 1.3
- (iv) 1.4
- (v) 1.5
- (vi) 1.6
- (vii) 1.7
- (viii) 2.0
- (ix) Combine the above power estimates to form a power curve so that the x-axis represents the expected odds
ratio and the y-axis represents the study's power. Discuss your power analysis in this light. Consider at what point
the study's power becomes adequate? What can be done to improve this study's power? Would you supplement
the study with additional information?